Gunjan Chhablani
Hello! I am a second-year Master's student at Georgia Tech, co-advised by Dhruv Batra and Zsolt Kira.
I also maintain EvalAI and have been a GSoC'23/GSoC'24 mentor at CloudCV. Previously, I spent two years, from 2020 to 2022, at Oracle, where I wore multiple hats as a developer and a Machine Learning Engineer within the the OCI language team. My main responsibilities revolved around designing and managing pipelines for training and evaluating language models. I hold a Bachelor's in Computer Science from BITS Goa, where I proudly secured the 3rd rank in my graduating class. Email / Resume / GitHub / Google Scholar / LinkedIn |

|
Publications |
|
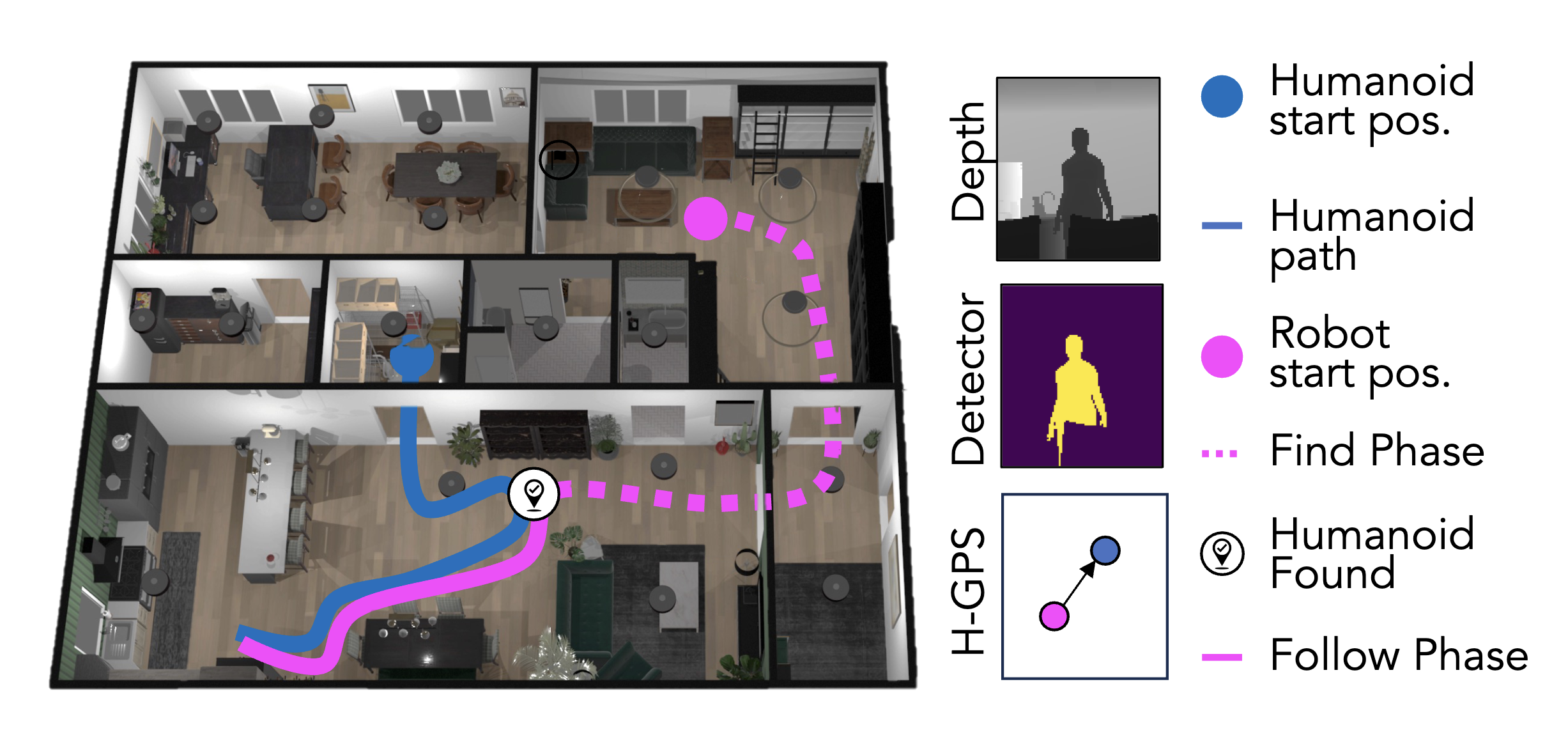
Curriculum Learning for GPS-Free Indoor Social NavigationGunjan Chhablani*, Madhura Keshava Ummettuguli*, Siva Kailas* CVPR Embodied AI Workshop, 2024 code / website |
|
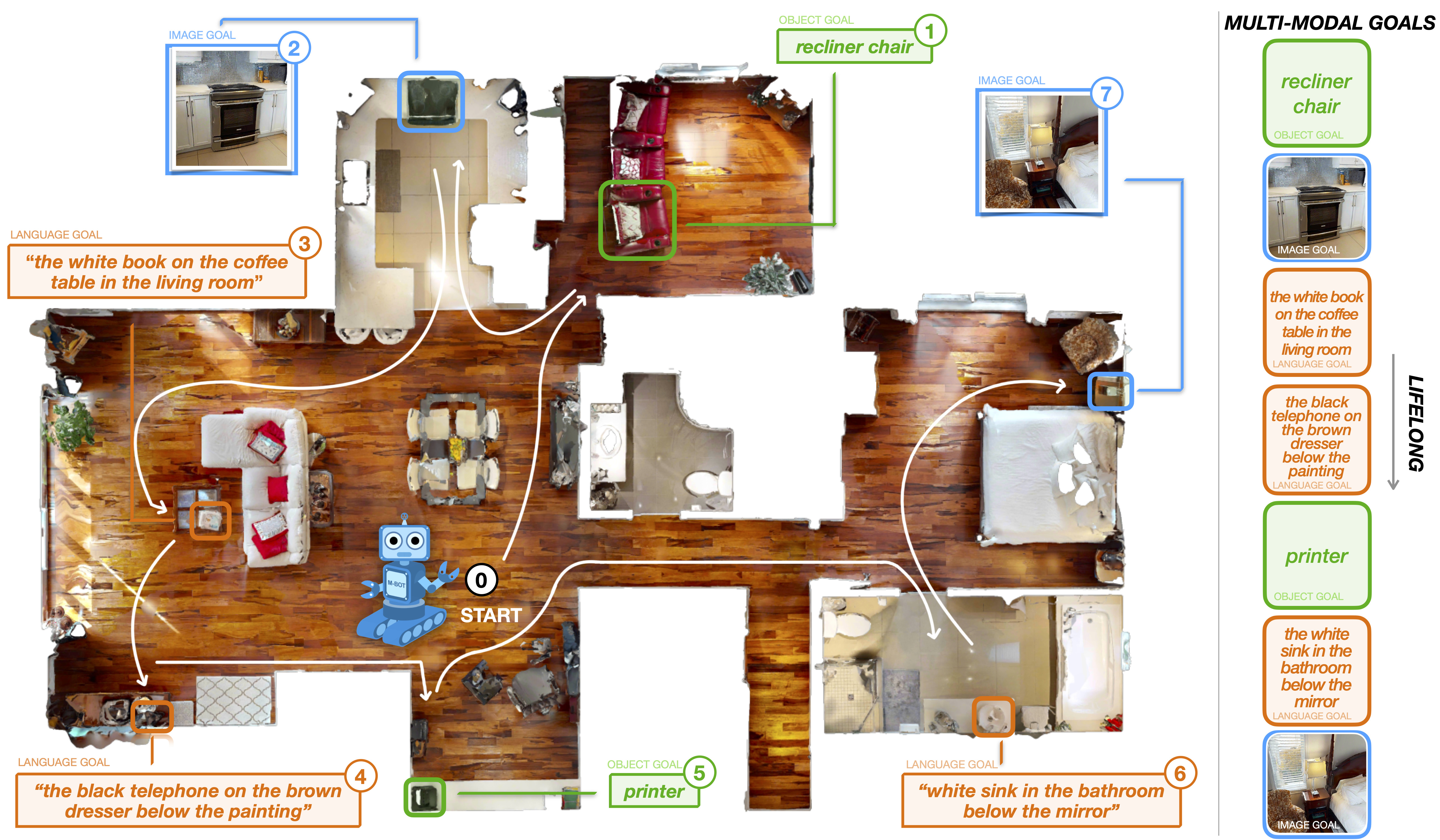
GOAT-Bench: A Benchmark for Multi-Modal Lifelong NavigationMukul Khanna*, Ram Ramrakhya*, Gunjan Chhablani, Sriram Yenamandra, Theophile Gervet, Matthew Chang, Zsolt Kira, Devendra Singh Chaplot, Dhruv Batra, Roozbeh Mottaghi CVPR, 2024 arxiv / code / website |
|
|
The HomeRobot Open Vocabulary Mobile Manipulation ChallengeSriram Yenamandra, Arun Ramachandran, Mukul Khanna, Karmesh Yadav, Devendra Singh Chaplot, Gunjan Chhablani, Alexander Clegg, Theophile Gervet, Vidhi Jain, Ruslan Partsey, Ram Ramrakhya, Andrew Szot, Austin Wang, Tsung-Yen Yang, Aaron Edsinger, Charles Kemp, Binit Shah, Zsolt Kira, Dhruv Batra, Roozbeh Mottaghi, Yonatan Bisk, Chris Paxton NeurIPS 2023 (Competitions Track), 2023 website |
|
|
MultiViz: Towards Visualizing and Understanding Multimodal ModelsPaul Pu Liang, Yiwei Lyu, Gunjan Chhablani, Nihal Jain, Zihao Deng, Xingbo Wang, Louis-Philippe Morency, Ruslan Salakhutdinov ICLR, 2023 arxiv / code / website |
|
|
PromptSource: An Integrated Development Environment and Repository for Natural Language PromptsStephen H. Bach, Victor Sanh, Zheng-Xin Yong, Albert Webson, Colin Raffel, Nihal V. Nayak, Abheesht Sharma, Taewoon Kim, M Saiful Bari, Thibault Fevry, Zaid Alyafeai, Manan Dey, Andrea Santilli, Zhiqing Sun, Srulik Ben-David, Canwen Xu, Gunjan Chhablani, Han Wang, Jason Alan Fries, Maged S. Al-shaibani, Shanya Sharma, Urmish Thakker, Khalid Almubarak, Xiangru Tang, Dragomir Radev, Mike Tian-Jian Jiang, Alexander M. Rush ACL (Demo), 2022 arxiv / code / website |
|
|
Multi-Task Prompted Training Enables Zero-Shot Task GeneralizationVictor Sanh, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Tali Bers, Stella Biderman, Leo Gao, Thomas Wolf, Alexander M. Rush ICLR, 2022 arxiv / code |
|
|
DRIFT: A Toolkit for Diachronic Analysis of Scientific LiteratureAbheesht Sharma*, Gunjan Chhablani*, Harshit Pandey*, Rajaswa Patil EMNLP (Demo), 2021 arxiv / code |
|
|
Datasets: A Community Library for Natural Language ProcessingQuentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, Joe Davison, Mario Šaško, Gunjan Chhablani, Bhavitvya Malik, Simon Brandeis, Teven Le Scao, Victor Sanh, Canwen Xu, Nicolas Patry, Angelina McMillan-Major, Philipp Schmid, Sylvain Gugger, Clément Delangue, Théo Matussière, Lysandre Debut, Stas Bekman, Pierric Cistac, Thibault Goehringer, Victor Mustar, François Lagunas, Alexander M. Rush, Thomas Wolf EMNLP (Demo), 2021 arxiv / code |
|
|
NLRG at SemEval-2021 Task 5: Toxic Spans Detection Leveraging BERT-based Token Classification and Span Prediction TechniquesGunjan Chhablani, Abheesht Sharma, Harshit Pandey, Yash Bhartia, Shan Suthaharan SemEval-2021 Workshop, ACL-IJCNLP, 2021 arxiv / code |
|
|
LRG at SemEval-2021 Task 4: Improving Reading Comprehension with Abstract Words using Augmentation, Linguistic Features and VotingAbheesht Sharma, Harshit Pandey, Gunjan Chhablani, Yash Bhartia, Tirtharaj Dash SemEval-2021 Workshop, ACL-IJCNLP, 2021 arxiv / code |
|
Design and source code from Jon Barron's website |